

Starting with NLP on AWS from scratch — NLP Series part 1 | by Carlos Cortez | Breaking the Cloud

I have 2 podcast, Imperio Cloud Podcast (imperiocloud.com) and "Up-to-date with AWS" Podcast (aldiaconaws.cortez.cloud)
It would be great to start segmenting our texts as well as the cover image, which is an Open Source software called Coreference created by Hugging Face, right? Let's go in parts ...
In case you are interested in hearing about Hugging Face and SageMaker, I spoke in depth a few days ago about this topic and its recent alliance with AWS here:
The learning curve
The learning curve is long and can get complex if we want to. For that there are flows and frameworks that will help us know where we are right now.

- Natural Language Processing (NLP) flow *
Many times we skip key steps before we really understand each of these procedures. For example, data ingestion, web scraping, text analytics, EDA (exploratory analysis, and much more)
Remember CRISP-DM?
It is a framework for data mining, which is now known more as Machine Learning, Deep Learning, Data Science, etc.

Essentials to get started on AWS
Always to each place we go, we keep this pair in our pocket:
- Python 3.x + boto3 *
Boto3 , is the AWS python library that will give us access to run and manage any resource within the cloud, as simple as import boto3, and have your private keys configured or your roles correctly created .
Pre-trained models
Pre-trained models help us to shorten research, training and analysis time, and not start inventing what already exists. and for this we can use cloud services.
Amazon Comprehend (Applied NLP) , It is a SaaS type service, which means that it is ready to consume an API with the AWS boto3 library and begin to obtain insights from the data. It contains models already trained by Amazon Web Services, which we can reuse to start our own, and we will start knowing this great service and start building interesting applications using other AWS services.
Hugging Face (advanced) , later we will play with transformers, tokenizers, and more with these Deep Learning models of Hugging Face.
Build your own models:
Once we have a good understanding of NLP's self-managed cloud services, we can move to the next level with Amazon Sagemaker.
Or, with your own containers, which we will also learn, or locally
NLP Open Source Libraries
I will mention these for now and we will surely know more than 2 of this list in the coming months:
NLTK
Spark NLP
CoreNLP
SpaCy
Pytorch
Tensorflow
etc..
Tools and IDEs
From now on we will begin to know and learn step by step, what it is like to work in the cloud with an IDE for Data Science, and learn about AI services on AWS.

I recommend taking a look at the following, some paid and some free.
Sagemaker Studio / Sagemaker Notebooks
Jupyter Notebooks / Jupyter Lab
Databricks
Google Colab
among others ...
To start for free, I suggest Databricks and Colab , the first one, has a community platform that allows you to create free clusters and they are eliminated if you do not use it for limited times, and Google's Colab, you can run it directly on your Google Drive, at no cost.
Deployment of my models in the cloud
It is not yet time to think about deploying, and yes, we will find many, many ways to do it, from the oldest to the most modern.
Traditional servers (VMs, Bare Metal)
Containers (such as AWS ECS, EKS, Fargate)
Without Servers (Functions as a Service)
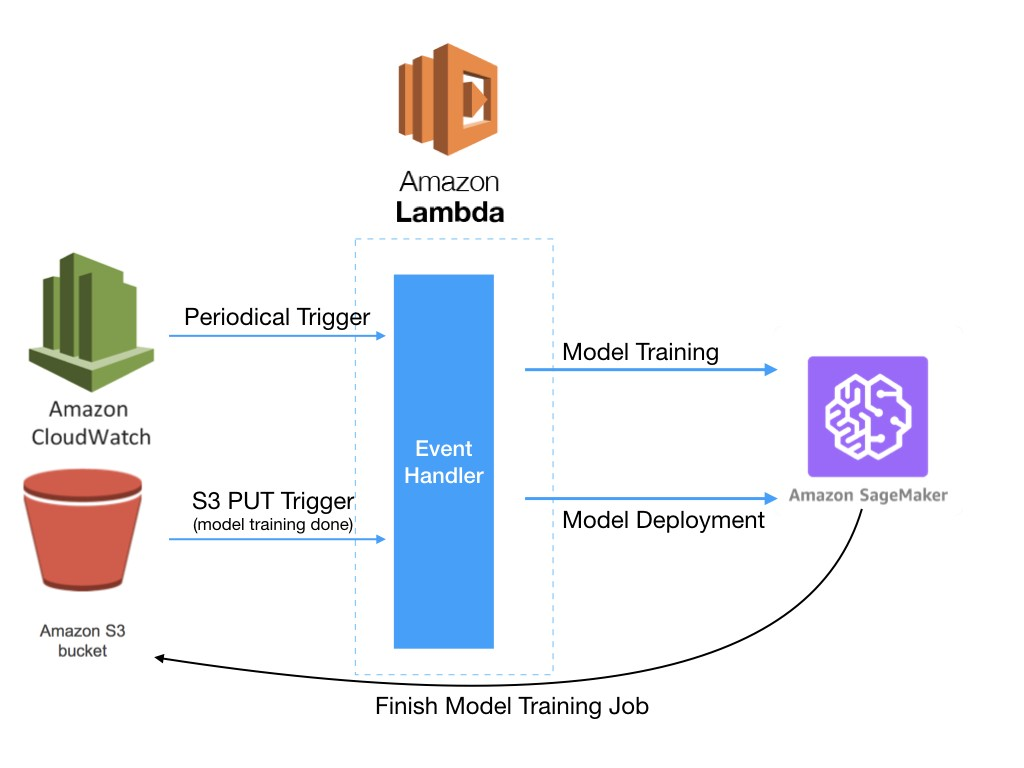
This is a very good way to start, putting together serverless and Sagemaker.
Think Serverless First
Now we can start working without having to run servers using AWS Lambda, AWS Step Functions, Sagemaker Pipelines, AWS CodePipeline, which are services already deployed in the cloud that we can use to speed up our development and start-up.
In the following posts we learn how to deploy with AWS Lambda and Amazon Comprehend.
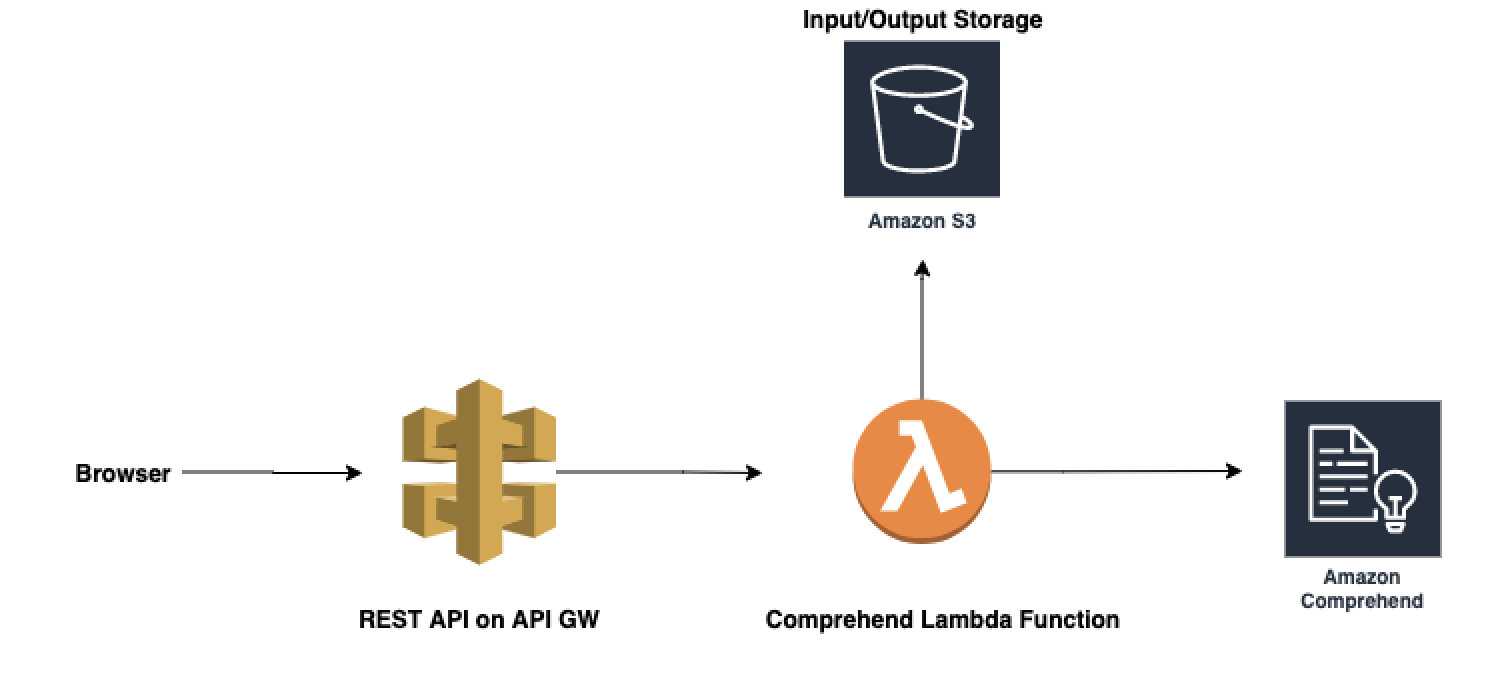
Amazon Comprehend and its superpowers
Can you imagine something as simple as writing a few lines of code to create a word detector and phrase extraction in just a few minutes instead of many hours of research? It is possible if you start to take advantage of Amazon Comprehend, a little Python and a couple of drops of Serverless
Phrase extraction:
We are using Python 3.6 here with boto3, the library
response **=** client**.**detect_key_phrases(
Text=’string’,
LanguageCode=’en’|’es’
)
Extraction of Entities, sentiment, language, syntax, topics, and document classification, are some of the additional things that we are going to do with Comprehend, as well as a specific version for Medicine, called Amazon Comprehend Medical
What do we continue with?
Data ingestion and text Analytics is part of the important bases to understand NLP, so in the next post, we will start to build our first data ingestion of a web, to be able to obtain data, texts, titles, in a data frame to play.
Next post: (on air on April 02)
(Post Original: Medium and Dev.cortez.cloud )
If you liked this post, give it a like, share and comment.
Learn by breaking things.
Subscribe to my channel, Breaking the Cloud and be Up to date with AWS at https://cortez.cloud
⭐Subscribe to my channel : http://bit.ly/aldiaconaws
videos, AWS news, analytics, reviews, demos, workshops
🔥🔥 Sígueme en mis redes 🔥🔥
follow me:
🦜 My Twitter: https://twitter.com/ccortezb
📺 Youtube Channel: http://bit.ly/aldiaconaws
📺 AWSUGPerú: https://www.youtube.com/awsusergroupperuoficial
📟 My Facebook: https://www.facebook.com/ccortezb/
🤳 My Instagram: ccortezbazan
📜My AWS Courses: https://cennticloud.thinkific.com
🕮 My blog — cortez.cloud
Thank you very much, I hope we see each other again
🔥🔥 About me 🔥🔥
Let me present to you, my little personal website https://www.Cortez.Cloud called “Breaking the Cloud”.
I will continue to create content each week from AWS on Al / ML, Serverless, Security and how to break the rules!
Also my next initiatives, workshops, courses, free videos, awsugperu and more.


